どーもTakeです。
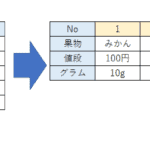
このたび兄弟ブログである「スーパー開発ブログ」で Pythonで画像から文字起こしをするサイトをつくりました!!!
記事はこちらです。
このページを作るのがかなり大変でした。。。。
CentOs7というサーバ上で「tesseract-ocr」と「pytesseract」というパッケージを使ってやったんですが、うまくいかないことばかり、、、
なので、構築手順を簡単にページにまとめました!
よければこのページを参考に作ってみてください!
- 画像から文字起こしするための環境構築する方法
- 実際にテスト用の Python スクリプトをつくって動作させるまで
画像から文字起こしするための環境構築
画像から文字起こしするための環境構築の方法について記述します。
この通りやればいけますが、下記を実行してエラーが出たら大抵うまくいきませんので、全部うまくいったことを確認してください。
「tesseract-ocr」と「pytesseract」をインストールする
下記コマンドを実行してパッケージを入れます。
|
1 2 3 |
# yum install gcc gcc-c++ make # yum install autoconf automake libtool # yum install libjpeg-devel libpng-devel libtiff-devel zlib-devel |
つぎに「tesseract-ocr」を実行するために必要な「leptonica」を入れます。
|
1 2 3 4 5 |
# wget http://www.leptonica.org/source/leptonica-1.76.0.tar.gz # tar -zxvf leptonica-1.76.0.tar.gz # ./configure # make # make install |
つぎに vim コマンドで「/etc/profile」に下記内容を追記します。
|
1 2 3 4 |
export LD_LIBRARY_PATH=$LD_LIBRARY_PAYT:/usr/local/lib export LIBLEPT_HEADERSDIR=/usr/local/include export PKG_CONFIG_PATH=/usr/local/lib/pkgconfig carried out source /etc/profileMake it effective |
そんで「tesseract-ocr」を入れます。
git コマンドが入っていない場合「yum install git」で入れます。
|
1 2 3 4 5 6 |
# git clone -b master https://github.com/tesseract-ocr/tesseract.git tesseract-ocr # ./autogen.sh # ./configure # make # make install # ldconfig |
「tessdata」で言語パッケージをとってくる
「tessdata」っていう言語パッケージを取ってきます。
下記コマンドを実行します。
|
1 2 |
git clone https://github.com/tesseract-ocr/tessdata.git mv tessdata /usr/local/share/tessdata |
あとは実際に動くか試してみます。
|
1 |
$ tesseract ims.png out -| jen |
上記は「img.png」って画像を読み込ませて「out」(テキストとして出力)されます。
日本語を文字起こししたい場合は jpn で言語指定します。
実行後に「Error」となく実行できればOK、out.txtの中身を確認して正常に動いていれば問題なしです。
ポイント!
「mv tessdata /usr/local/share/tessdata」を絶対に忘れないこと!!!
しかも「cp」コマンド(コピー)ではなく「mv」コマンド(移動)であること!です!
なんでかわからないですが、「cp」コマンドだと旨く読み込まれなかったです。
わたしはそもそも「mv」コマンドを忘れて実行してしまい下のようなエラーがでて私は詰みました笑
|
1 2 3 4 5 6 7 8 9 |
# 実行しようとしたときの出来事 $ tesseract ims.png out -| jen Error in pixReaddenTiff: function not present Error in pixReadMem: tiff: no pix returned Error in pixaGenerateFontFromStrina: pix not made Error in bnfCreate: font pixa not made Tesseract Open Source OCR Engine v5.0.0-alpha-20210401-118-g1c77 with Leptonica Error in pixReadStreamPng: function not present Error in pixReadStrean: png: no pix returned Error in pixRead: pix not read Error during processing |
「pytesseract 」をインストールする
ここまでくればあとは「pip install pytesseract 」を実行します。
ここまでエラーなしでいけていればOKです。
参考サイト:
実際にPythonコードを書いてみる
実際に「tesseract」を python上で動作させます。
下記内容を pythonファイルとして保存(今回は test.py)とします。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
from pytesseract import pytesseract from PIL import Image # 読み込み対象ファイルの指定 img = Image.open("./img.png", "r") # tesseractコマンドのインストールパス pytesseract.tesseract_cmd = "/usr/local/bin/tesseract" # 文字列として出力できる。 result = pytesseract.image_to_string(img, lang="eng+jpn") print(result) |
そして「python test.py 」と実行すればコマンドライン上に画像に含まれるメッセージが出力されます。
処理の中身は超簡単です。
まず img.png っていう画像ファイルを読み込んで「/usr/local/tesseract」を呼び出して実行して変数に格納し、
その変数を出力するだけのスクリプトです。
最後に
いかがでしたでしょうか?
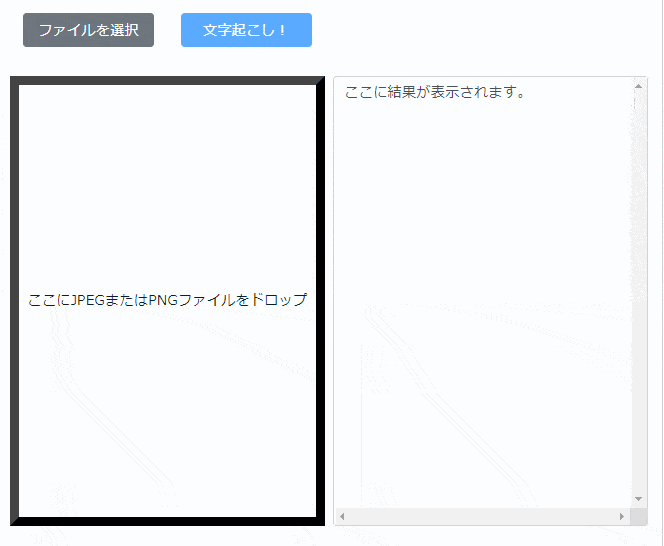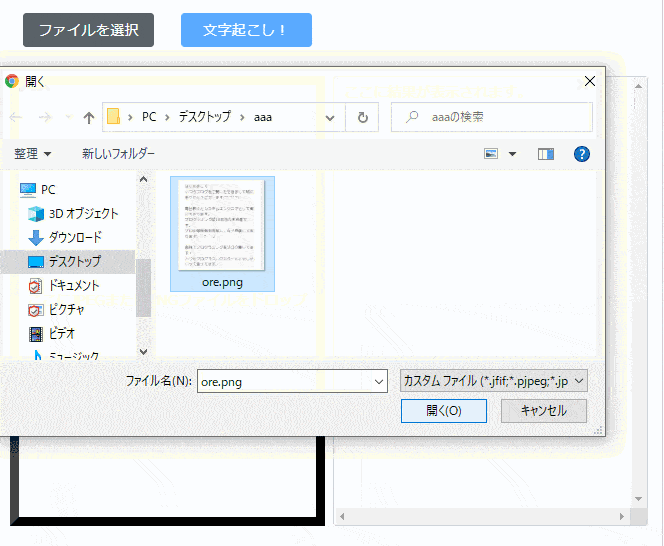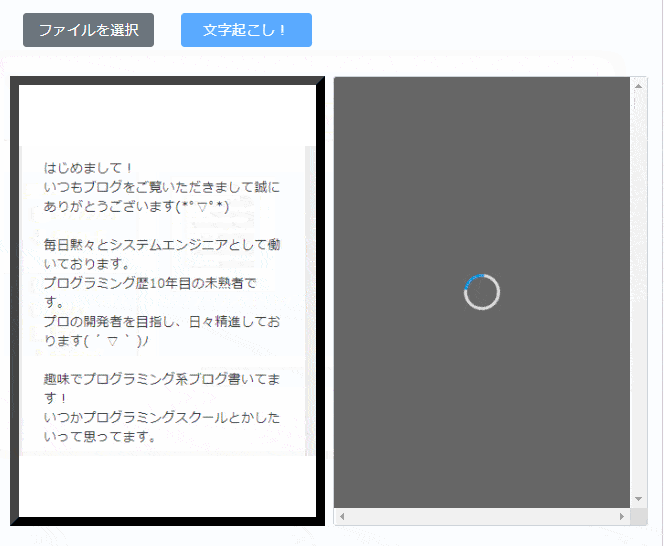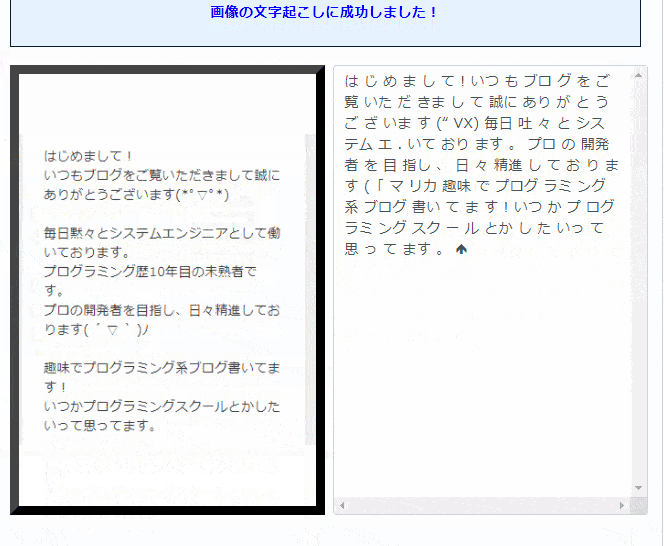
Pythonで画像から文字起こしをする方法を解説しました。
わたしの兄弟ブログである「スーパー開発ブログ」のこちらの記事に実際に動作するものが乗っています。
ただ英語は精度がかなりいいんですが、日本語が精度が悪いです。。。
ですが、結構面白いサイトなのでぜひチェックして見てください!
ではでは。